분류 전체보기
-
공홈 메뉴얼로 Flutter공부 시작2024.01.17
-
GPT 선생님과 Flutter 시작하기(Visual Studio Code설치)2024.01.17
-
GPT선생님과 Flutter로 앱 개발하기(개발시작)2024.01.16
-
GPT선생님과 Flutter로 앱 개발하기(설치)2024.01.16
-
GPT로 앱을 개발해 보기로 했다.2024.01.16
-
MySQL 파티션 키 컬럼을 varchar 타입으로 하는 방법2024.01.16
-
오라클 DB계정 생성 ORACLE CREATE USER2024.01.16
-
오라클 ASM 사용률 변화 확인/수집 및 현황 보고를 위한 쿼리2023.12.12
ORA-04031 shared pool, unknown object, sga heap(5,0), ktmc_dlm_lck
ORA-04031 shared pool 메모리 단편화
shared pool에서 연속된 블록공간을 확보할 수 없을때 발생한다.
일반적으로 해결방법은 4가지이다.
- shared_pool_size 및 shared_pool_reserved_size 추가확보
- 많은공간을 사용하는 프로시저 sql등을 keep
- flush shared pool이나 db 재기동
- Literal SQL 을 찾아 해결한다.
위의 방법은 구글링하면 많이 나오는 답변이고,
대채로 일반적인 상황해서는 해결이 된다.
하지만 내가 겪은 상황은 다르다.
위의 문제로 해결할 수 없는 상황이다.
이유는 아래와 같다.
ktmc_dlm_lck
바로 ktmc_dlm_lck 라는 문구가 ORA-04031에러 메시지와 함께 나왔다는것.
이 문구로 구글링을 하면 자료가 별로 없다.
보통 에러를 확인할때에는 뒤에 붙은 문자열로 검색해야
원인을 빠르게 찾을 수 있다.
저 문자열을 oracle support에서 검색하면
단 하나의 자료를 확인할 수 있다.
( ORA-04031 Due To High Shared Pool Usage To "GCS DYNAMIC RESOURCES FG" With In-Memory Option (DBIM) (Doc ID 2200825.1)
해당 에러는 RAC환경에서 inmemory의 DLM,KCL lock과 관련이 있다.
실제로 해당 문서에서 제공하는 쿼리를 수행하면
일관성을 위한 lock을 수행하는데 필요한 메모리 공간이 얼마나 많이
사용되고 있는지 확인 할 수 있었다.
SELECT inst_id,decode(con_id,1,'1','*') con_id,pool,name , ROUND (SUM (bytes/ 1024 / 1024 / 1024), 2) gb
FROM gv$sgastat s
WHERE (pool = 'shared pool' and name in ('ktmc_dlm_lck','PDBHP') ) or (pool= 'numa pool' and name like 'gcs dynamic resources %')
GROUP BY inst_id,decode(con_id,1,'1','*'),pool,name
order by 1,2;결과는 보통 아래처럼 나온다.
INST_ID C POOL NAME GB
---------- - ------------ -------------------------- ----------
1 * shared pool ktmc_dlm_lck 7.6
...
1 * shared pool gcs dynamic resources fg 21.79
하지만 19c환경에서는 조건절의
pool = 'numa pool' 이라는 구문을 빼야 결과가 나온다.
이미 12c환경에서 bug로 판명이나서 patch파일이 존재한다.
하지만 내 환경은 19c이다보니 패치적용이 불가능한 상황.
이 경우 oracle에 sr오픈하여 정확한 진단을 받고
진행하는게 맞다.
끝.
'└ 01-02.ORACLE > ORA-' 카테고리의 다른 글
| event ORA$AT_OS_OPT_SY_????, ORA-27403, ORA-00600 (1) | 2024.09.05 |
|---|---|
| ORA-65096: invalid common user or role name (공통 사용자 또는 롤 이름이 부적합합니다.) (1) | 2023.12.08 |
event ORA$AT_OS_OPT_SY_????, ORA-27403, ORA-00600
업무 테이블 DELETE의 지연 발생 (평소 초단위 수행건이 5시간 이상 수행중)
모니터링 솔루션을 통해 확인함.
1. DELETE를 수행중이던 세션이
enq : TX - index contention 락이 발생하며 대기중.
enq : TX - index contention
타 세션이 DML에 의해 TX - exclusive Lock을 획득한 상태에서
데이터가 INSERT되면서 인덱스 리프노드가 SPLIT되는 중에
내 세션의 DML수행으로 SPLIT중인 해당 리프노드를
변경하고자 하는 경우 이 이벤트가 발생한다.
2. 해당 락을 잡고 있는 세션을 추적하니
INSERT를 수행중이던 세션을 확인함.
이 세션도 gc buffer busy acquire 이벤트와 함께 10시간 넘게 대기중.
3. INSERT를 수행중이던 세션과 함께 대기중이던 세션 발견.
SYS에서 DBMS_SCHEDULER가 수행중임을 확인함.
20시간이 넘도록 gc cr request 이벤트와 함께 대기중이었고
이 세션을 KILL하니 대기중이던 작업이 완료됨.
원인 확인
DBMS_SCHEDULER에서 수행중이던 작업 확인해 보았다.
아래 쿼리가 수행중이었다.
SELECT /*+ opt_param('_optimizer_use_auto_indexes' 'on')
parallel_index(t, "INDEX_NAME", 23)
dbms_stats
cursor_sharing_exact
use_weak_name_resl
dynamic_sampling(0)
no_monitoring
xmlindex_sel_idx_tbl
opt_param('optimizer_inmemory_aware' 'false')
no_substrb_pad
no_expand
index_ffs(t, "INDEX_NAME") */
Count(*) AS nrw,
Count(DISTINCT Sys_op_lbid(161708, 'L', t.ROWID)) AS nlb,
NULL AS ndk,
Sys_op_countchg(Substrb(t.ROWID,1,15),1) AS clf
FROM "OWNER"."TABLE_NAME" t
WHERE "COLUMN_NAME1" IS NOT NULL
OR "COLUMN_NAME2" IS NOT NULL1. 원인 1
해당 쿼리의
opt_param('_optimizer_use_auto_indexes' 'on')
구문을 보면 DBMS_AUTO_INDEX와 연관이 있어보인다.
아래 테이블로 AUTO_INDEX와 연관된 정보를 확인할 수 있다.
DBA_AUTO_INDEX_VERIFICATIONS
DBA_AUTO_INDEX_STATISTICS
DBA_AUTO_INDEX_CONFIG
DBA_AUTO_INDEX_EXECUTIONS
DBA_AUTO_INDEX_SQL_ACTIONS
DBA_AUTO_INDEX_IND_ACTIONS
이중에 DBA_AUTO_INDEX_CONFIG 테이블을 확인해보면
AUTO_INDEX_MODE 행이 있는데
이것의 PARAMETER_VALUE값이 OFF가 아닌 경우에만
이번의 이슈가 DBMS_AUTO_INDEX 기능때문이라는 것으로
유추해볼 수 있다.
하지만 이번 사례는 해당 값이 OFF이므로 AUTO_INDEX와는
연관이 없었다.
그러면 해당 쿼리는 뭐때문에 수행되었는가?
2. 원인 2.
이 쿼리의 수행목적은 아래 뷰테이블의 수집 목적일 가능성이 크다.
V$INDEX_USAGE_INFO
DBA_INDEX_USAGE
아래의 히든 파라미터값이 TRUE인 경우 해당 인덱스 정보가 자동수집된다.
Default가 TRUE이다.
NAME DESCRIPTION DEFAULT
------------------------- ---------------------------------------- -------
_iut_enable Control Index usage tracking TRUE
_iut_max_entries Maximum Index entries to be tracked 30000
_iut_stat_collection_type Specify Index usage stat collection type SAMPLED
**참고 : http://ksun-oracle.blogspot.com/2020/05/12cr2-index-usage-tracking-manual.html
원인은 알았고.
그럼 왜 종료되지 않고 계속 waing되었는가?
DBMS_SCHEDULER 작업 상태 확인
아래 쿼리로 스케줄러에서 수행하는 JOB을 확인할 수 있다.
SELECT LOG_DATE, OWNER, JOB_NAME, STATUS, SESSION_ID
,ADDITIONAL_INFO
FROM DBA_SCHEDULER_JOB_RUN_DETAILS
WHERE JOB_NAME LIKE '%AT_OS_OPT_SY%'
ORDER BY ACTUAL_START_DATE;결과를 보면 지금까지 수행한 INDEX통계수집 정보를 날짜별로 확인가능하다.
JOB_NAME => ORA$AT_OS_OPT_SY_????
STATUS => JOB수행결과 (이 부분이 STOPPED였다.)
ADDITIONAL_INFO => 작업실패 원인
작업실패 원인이
REASON='Job slave process was terminated"
인 것 을 확인할 수 있었다.
Job slave process가 비정상상태인것이 원인이었다.
ALERT log확인
그리고 alert.log도 확인해 보았다.
해당 스케줄러가 수행중인 초기에는 log가 떨어진게 없었지만
약 10시간 이후부터 trace파일과 함께 아래 에러메시지가 떨어졌다.
System State dumped to trace file /pwd/DB_NAME_j000_3043.trc
Errors in file /pwd/DB_NAME_p00r_34422.trc
ORA-00600: internal error code, arguments: [15709], [29], [1], [2], [27], [P00R], [34422], [],
ORA-27403: scheduler stop job event
Incident details in: /pwd/incident/incdir_791189/DB_NAME_j000_3043_i791189.trc
ORA-00600의 아규먼트를 ORACLE SUPPORT에서 조회해도
내용이 나오지 않으므로
SR 오픈하여 진행해야한다.
결론
해당 이슈는 DBMS_SCHEDULER의 JOB에 의한
INDEX 통계정보 수집중 Job Process의 이슈로 인한 비정상 수행이
원인이 되어 해당 테이블에 Lock이 발생.
이후 업무 쿼리는 대기상태에 돌입.
해당 이슈로 인한 ORA-600에러 발생으로
정확한 진상규명이 어려워 ORACLE에 SR오픈하여 파악하는게 맞다.
끝.
'└ 01-02.ORACLE > ORA-' 카테고리의 다른 글
| ORA-04031 shared pool, unknown object, sga heap(5,0), ktmc_dlm_lck (1) | 2024.09.11 |
|---|---|
| ORA-65096: invalid common user or role name (공통 사용자 또는 롤 이름이 부적합합니다.) (1) | 2023.12.08 |
공홈 메뉴얼로 Flutter공부 시작
먼저 공홈 주소로 들어가서 처음부터 공부를 시작해 보도록 하겠다.
https://codelabs.developers.google.com/codelabs/flutter-codelab-first?hl=ko#2
첫 번째 Flutter 앱 | Google Codelabs
이 Codelab에서는 멋진 이름을 무작위로 생성하는 Flutter 앱을 빌드하는 방법을 알아봅니다.
codelabs.developers.google.com
F1버튼으로 Flutter:New Project선택
F1버튼을 누르면 자동으로 검색을 열어준다.
여기서 flutter 를 치면
아래와 같이 Flutter: New Project가 나오는데
이걸 선택한다.

Application 선택

Project의 파일이 저장될 경로를 지정한다.

그리고 프로젝트의 이름을 입력하고 Enter.

폴더의 콘텐츠를 신뢰하느냐를 물어본다. yes를 선택. (no선택시 flutter기능 상당부분을 사용할수 없음)

초기 앱 시작을 위해 아래 파일을 연다.
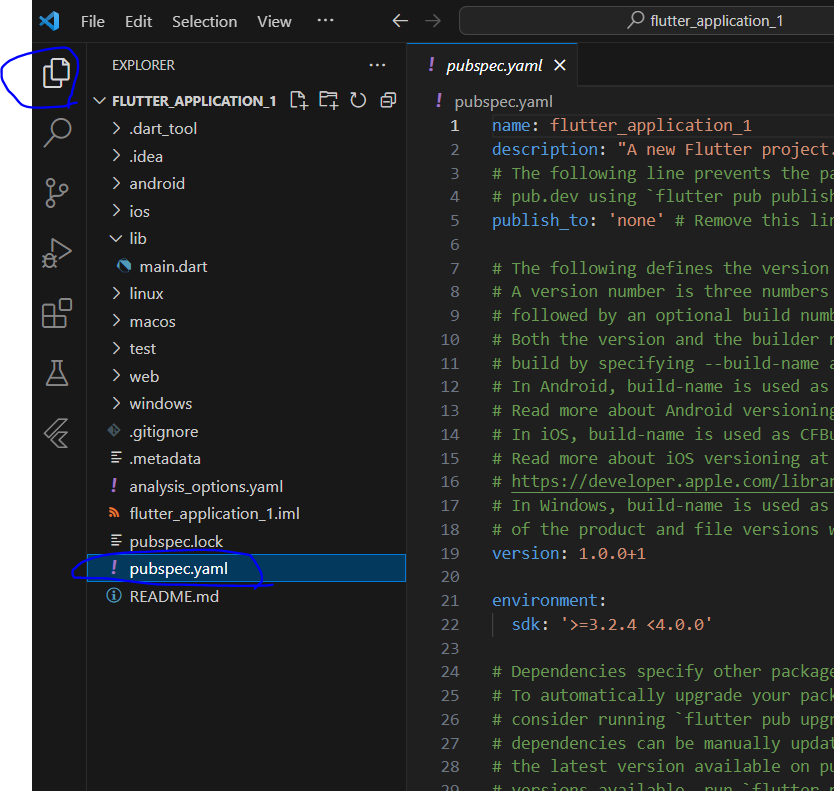
pubspec.yaml의 내용을 아래 코드로 바꿔준다.
name: namer_app
description: A new Flutter project.
publish_to: 'none' # Remove this line if you wish to publish to pub.dev
version: 0.0.1+1
environment:
sdk: '>=2.19.4 <4.0.0'
dependencies:
flutter:
sdk: flutter
english_words: ^4.0.0
provider: ^6.0.0
dev_dependencies:
flutter_test:
sdk: flutter
flutter_lints: ^2.0.0
flutter:
uses-material-design: true
#pubspec.yaml 파일은 앱에 관한 기본 정보(예: 현재 버전, 종속 항목, 함께 제공될 애셋)를 지정함.
#앱 이름을 namer_app이 아닌 다른 이름으로 지정했다면 이에 따라 첫 번째 줄을 변경해야 합니다.
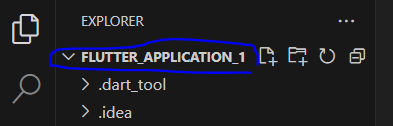
위 코드의 최상단에 작성된 name: namer_app를
위 스샷처럼 앱 이름으로 변경한다.
나는 FLUTTER_APPLICATION_1이니 이것으로 변경하겠다.
대소문자를 구문하는지 모르겠어서 똑같이 대문자로 했다.
또 다른 구성 파일 analysis_options.yaml을 열어서 수정한다.

include: package:flutter_lints/flutter.yaml
linter:
rules:
prefer_const_constructors: false
prefer_final_fields: false
use_key_in_widget_constructors: false
prefer_const_literals_to_create_immutables: false
prefer_const_constructors_in_immutables: false
avoid_print: false
이 파일은 코드를 분석할 때 Flutter의 엄격성 정도를 결정합니다.
이번이 Flutter를 처음 사용하는 것이므로 분석 도구에 쉬엄쉬엄하자고 지시하는 것입니다.
이는 나중에 언제든지 조정할 수 있습니다.
사실 실제 프로덕션 앱을 게시할 때가 가까워지면 분명 이보다는 더 엄격하게 분석 도구를 만들게 됩니다
lib/ 디렉터리 아래의 main.dart 파일을 열어서 수정한다.

아래 코드로 변경
import 'package:english_words/english_words.dart';
import 'package:flutter/material.dart';
import 'package:provider/provider.dart';
void main() {
runApp(MyApp());
}
class MyApp extends StatelessWidget {
const MyApp({super.key});
@override
Widget build(BuildContext context) {
return ChangeNotifierProvider(
create: (context) => MyAppState(),
child: MaterialApp(
title: 'Namer App',
theme: ThemeData(
useMaterial3: true,
colorScheme: ColorScheme.fromSeed(seedColor: Colors.deepOrange),
),
home: MyHomePage(),
),
);
}
}
class MyAppState extends ChangeNotifier {
var current = WordPair.random();
}
class MyHomePage extends StatelessWidget {
@override
Widget build(BuildContext context) {
var appState = context.watch<MyAppState>();
return Scaffold(
body: Column(
children: [
Text('A random idea:'),
Text(appState.current.asLowerCase),
],
),
);
}
}
이렇게 어플을 만들기위한 초기 셋팅이 완료되었다.
이렇게 스크린샷을 찍고 설명을 공홈에 있는것 그대로 가져다 쓰는건
영~ 시간낭비도 심하고 공부하는데 방해가 되므로
공부하실분은 공홈에 들어가서 하시고..
다음부터는 간략하게 필요한것만 정리해서 올려야겠다..
'└ 01-01.Flutter' 카테고리의 다른 글
| GPT 선생님과 Flutter 시작하기(Visual Studio Code설치) (0) | 2024.01.17 |
|---|---|
| GPT선생님과 Flutter로 앱 개발하기(개발시작) (0) | 2024.01.16 |
| GPT선생님과 Flutter로 앱 개발하기(설치) (0) | 2024.01.16 |
| GPT로 앱을 개발해 보기로 했다. (0) | 2024.01.16 |
GPT 선생님과 Flutter 시작하기(Visual Studio Code설치)
이전에 flutter로 개발하기 위해서 android studio를 설치 했는데
공식 홈페이지에 있는 메뉴얼로 공부를 하려고 하니
공홈에서는 VSCode를 사용하더라..
UI가 훨씬 간결하고 복잡하지 않아서 이게 더 좋아보여서..
GPT선생님께 여쭤보았다.
Visual Studio Code와 Android Studio의 차이


선생님께서 두 프로그램 모두 훌륭하다고 하여
나는 더 간편해 보이는 VSCode를 사용해 보겠다.
Visual Studio Code 설치


next만 계속 눌러서 설치를 완료했다.
이제 flutter와 dart확장 설치를 한다.

나는 딱 Flutter와 Dart만 설치했다.
나머지 Flutter어쩌구저쩌구는 설치하지 않았다.
이렇게 Visual Studio Code설치도 마쳤으니
실습을 진행해 보도록 하겠다.
'└ 01-01.Flutter' 카테고리의 다른 글
| 공홈 메뉴얼로 Flutter공부 시작 (0) | 2024.01.17 |
|---|---|
| GPT선생님과 Flutter로 앱 개발하기(개발시작) (0) | 2024.01.16 |
| GPT선생님과 Flutter로 앱 개발하기(설치) (0) | 2024.01.16 |
| GPT로 앱을 개발해 보기로 했다. (0) | 2024.01.16 |
GPT선생님과 Flutter로 앱 개발하기(개발시작)
설치는 완료되었고
이제 정말 개발을 시작하도록 하자..
하지만,, 나는 아무것도 모른다..
도대채 뭐부터 해야하는지.. 어떤 메뉴에 들어가서
어떤 command를 쳐야하며, 어떤 순서로 쳐야하는지.. 아무것도 모르는 진성 초보이다..
그러니 선생님께 물어보도록 하자.


선생께서도 본인한테 직접 물어보기보다는
먼저 공부를하라고 알려주신다..
공부를 하기위해서는 공식 문서를 참고하라고 친절히 주소까지 알려주시네..
내가 flutter에 대해서 아무것도 모르니
선생님께 질문을 하기 위해서는 나도 어느정도 flutter에 대해서 공부를 해야한다.
이건 당연하다고 생각하고, 공식 문서를 보면서 차근차근 공부를 시작하겠다.
공부를 하면서 간단한 앱을 목표로 프로젝트를 만들면서
막히는 부분이나 모르겠으면 그때마다 선생님께 물어봐야 겠다.
선생님이 아무리 만능이라고 하더라도
질문하는 능력이 중요하다.
그 능력을 키우기 위해서는 나도 전문가까지는 아니더라도
기본적으로 필요한 지식은 공부를 해야겠다.
'└ 01-01.Flutter' 카테고리의 다른 글
| 공홈 메뉴얼로 Flutter공부 시작 (0) | 2024.01.17 |
|---|---|
| GPT 선생님과 Flutter 시작하기(Visual Studio Code설치) (0) | 2024.01.17 |
| GPT선생님과 Flutter로 앱 개발하기(설치) (0) | 2024.01.16 |
| GPT로 앱을 개발해 보기로 했다. (0) | 2024.01.16 |
GPT선생님과 Flutter로 앱 개발하기(설치)
먼저 나는 개발은 하나도 모르는 평범한 직장인이고,
앱 개발을 하기위해서는 필요한 언어들이 많을텐데..
이것저것 검색해본 결과
나는 Flutter를 사용해서 앱을 만들어 보기로 했다.
Flutter는 Dart언어 하나만 할 줄 알면 Android & iOS 두가지 어플을 동시에
만들수가 있다.
원래는 안드로이드용 어플과 iOS용 어플을 개발하기 위해서는 서로 다른 언어를 사용해서 개발하는것으로 알고 있는데,
이런 좋은게 생겼더라...
서두는 됐고,
일단 설치부터 선생님께 물어보도록 하자.
먼저 지난 글에 작성한것처럼
나는 GPTs에서 Flutter GPT 챗봇을 등록했고,
이 선생님께 여쭤보도록 하겠다.
영어로 하면 결과가 더 빨리 나오겠지만,,
나는 영어도 잘 못하므로.. 한글로 물어보겠다.

와우 설치할때 필요한 것들을 간략하게 알려준다.
같은 질문을 그냥 GPT선생께 물어보면 전혀 다른 답을 주던데.. 역시 좋구만.
GPT선생께서 알려주신대로 설치를 진행하도록 하겠다.
선생님이 알려주신것중 이해가 안가는것은
그것에 대해 자세히 알려달라고 물어보면 자세히 알려준다.
나는 환경변수 설정이 잘 안돼서 그것에 대해 물어보았다.

환경변수 Path에 flutter의 bin경로를 추가해야하는데,
시스템환경변수가 안보여서 물어봤더니 이렇게 더 자세히 알려준다.
GPT선생님께서 알려주신대로 모두 설치를 완료했다.
별로 막히는 부분은 없었다.
flutter에서도 추가로 필요한것들은 아주 자세히 알려주더라..
환경변수까지 설정했으면
cmd창에서 flutter doctor를 쳐본다.
에러가 나면 환경변수 설정이 잘 못 된것이므로 다시 확인하자.
정상화면은 아래와 같다.

이처럼 설치가 정상적으로 완료되었으면
모든 항목에 대해 체크가 되고
No Issues found!라는 메시지가 나온다.
항목별로 문제가 있으면 체크표시대신 느낌표[ ! ]나 엑스[ X ]표시가 나타나고
뭐가 문제인지 어떻게 해결할 수 있는지 domain주소나 명령어가 나오니 그대로 복사해서
붙여넣기 하면 간단하게 해결 가능하다.
'└ 01-01.Flutter' 카테고리의 다른 글
| 공홈 메뉴얼로 Flutter공부 시작 (0) | 2024.01.17 |
|---|---|
| GPT 선생님과 Flutter 시작하기(Visual Studio Code설치) (0) | 2024.01.17 |
| GPT선생님과 Flutter로 앱 개발하기(개발시작) (0) | 2024.01.16 |
| GPT로 앱을 개발해 보기로 했다. (0) | 2024.01.16 |
GPT로 앱을 개발해 보기로 했다.
참고로 개발의 개도 모르는 평범한 직장인이다..
DBA로 근무를 하고 있으니.. 완전히까지는 아니고 조금? 살짝 c언어가 뭔지 아는정도? ㅋ..
먼저 gpt에 들어가면 GPTs메뉴가 보인다.
최근 엄청난 화재를 이어가고 있는 gtp shop이다.
이 shop에서 내가 앱을 만들기 위해 도움을 주는 챗봇을 고른다.

GPTs에 들어가면 아래와같은 화면이 나오는데,
나는 앱을 만들기위해서 flutter를 사용할것이므로,
flutter를 검색한다.

내가 선택한 챗봇은 Flutter GPT라는 챗봇이다.
앞으로 이 챗봇을 사용해서 앱을 개발해 보도록 하겠다.
참고로 GPTs를 사용하기 위해서는 plan upgrade가 필요하다.
나는 22달러를 내고 plan upgrade를 했다.
주식이 아닌 지식에 가치투자를 하기로 했고
월 22달러는 매우 저렴하다고 생각하다.
물론 이 gpt를 아주 잘 이용해 먹어야겠지만. ㅋ
'└ 01-01.Flutter' 카테고리의 다른 글
| 공홈 메뉴얼로 Flutter공부 시작 (0) | 2024.01.17 |
|---|---|
| GPT 선생님과 Flutter 시작하기(Visual Studio Code설치) (0) | 2024.01.17 |
| GPT선생님과 Flutter로 앱 개발하기(개발시작) (0) | 2024.01.16 |
| GPT선생님과 Flutter로 앱 개발하기(설치) (0) | 2024.01.16 |
MySQL 파티션 키 컬럼을 varchar 타입으로 하는 방법
MySQL에서는 RANGE파티션을 생성할 때
날짜기준 파티션으로 만들기 위해서는
파티션 키 컬럼의 데이터타입이 DATE나 INT여야 한다.
VARCHAR타입 컬럼을 키로 잡았을때는 에러가 발생한다.
하지만 VARCHAR타입을 키 컬럼으로 잡기 위해서는
PARTITION BY RANGE COLUMNS(key_column)을 사용하면 된다.
COLUMNS가 핵심이다.
이 옵션을 설정해야 되더라..
오라클 DB계정 생성 ORACLE CREATE USER
CREATE USER

오라클 공식 메뉴얼을 토대로 계정을 생성해 보자.
참고로 내가 다녔던 1금융에서 생성했던 방식을 그대로 사용하겠다.
(특별한건 아마 없을것 같다.)
DB계정생성
CREATE USER TEST_USR --사용할 USER명을 기입한다.
IDENTIFIED BY "Test123!@" --PW를 쌍따옴표 안에 기입한다. (특수문자,대소문자 구분 필요시)
DEFAULT TABLESPACE TS_IMSI --TABLE&INDEX생성시 T/S를 명시하지 않아도 자동으로 이 부분에 설정한 T/S에 생성된다.
QUOTA UNLIMITED ON TS_IMSI --DEFAULT T/S에서 사용할 SIZE를 설정한다. [QUOTA 10M ON]으로 하면 10MB까지만 사용할수 있다는 뜻이다.
PROFILE PF_TEST --PROFILE을 설정한다. PROFILE에는 세션에 대한 각종 차단등 보안관련 설정이 가능하다.
위와 같이 줄바꿈하면서 쓰지않고 한줄로 써도 된다.
모든 옵션을 빼고 CREATE USER TEST_USR IDENTIFIED BY "Test123!@" 만 날려줘도 에러없이 생성된다.
대신 옵션중 일부는 DEFAULT가 설정된 값으로,
일부는 아무값도 들어가지 않게 되므로 ALTER문으로 추가로 작업해주어야 한다.
DEFAULT TABLESPACE를 지정해 주지 않으면
파라미터에 설정되어있는 DEFAULT T/S를 따라가게 되어
USERS 혹은 SYSTEM이 잡힐수도 있으니 큰 일 날 수 있다.
(물론 사용하는 환경의 파라미터를 보면 알 수 있다.)
추가로 다른 옵션을 부여할 필요없이 위와 같이 생성하면
업무에 아무 문제없이 사용할 수 있다.
DB계정 생성후 추가로 해야하는 작업
CREATE USER만 수행했다고 해서 바로 로그인을 할 수 있는것은 아니다.
DB접속권한과 기타 필요한 권한을 부여해 줘야한다.
일반적으로 아래 권한은 기본적으로 부여한다.
GRANT CONNECT TO USER_NAME; --CONNECT라는 ROLE을 USER에 부여를 한다.
GRANT CREATE SESSION TO USER_NAME; --DB를 접속할수 있는 CREATE SESSION권한을 부여한다.
## 특정 테이블에 대한 권한을 부여하려면 아래와 같다.
GRANT SELECT ON OWNER.TABLE_NAME TO USER_NAME; --OWNER.TABLE_NAME에 조회권한을 USER에 부여한다.
GRANT INSERT, UPDATE, DELETE ON OWNER.TABLE TO USER_NAME; --삽입,수정,삭제 권한을 부여한다.
## DB접속 권한을 부여하고 싶다면 위의 권한중 하나만 부여하면된다.
## CONNECT ROLE에는 CREATE SESSION 권한이 부여되어있고 이 ROLE을 USER에 부여하는 개념이다.
권한 관련해서는 따로 글을 남기도록 하겠다.
'└ 01-02.ORACLE > SQL' 카테고리의 다른 글
| 오라클 ASM 사용률 변화 확인/수집 및 현황 보고를 위한 쿼리 (0) | 2023.12.12 |
|---|---|
| ORACLE RMAN 백업 진행 상황을 확인하는 쿼리 RMAN Backup status check (2) | 2023.12.05 |
| 오라클 HWM와 실제로 사용하는 블록 확인 쿼리. 리오그 대상 찾는법. ORACLE REORG HWM (0) | 2023.12.01 |
오라클 ASM 사용률 변화 확인/수집 및 현황 보고를 위한 쿼리
매월 정기적으로 해야하는 작업이 있다.
바로 공간 사용률 분석이다.
매월 수집하는 이 정보가 누적되면
월,분기,년 단위로 DB 공간 사용률 확인 및 앞으로 필요한 공간의 예측이 가능할 것이다.
SELECT
GROUP_NAME,
TOTAL AS TOTAL_GB,
USED AS USED_GB,
FREE AS FREE_GB,
USE_PCT AS USE_PCT_PER,
DISK_SIZE AS DISK_SIZE_GB,
DISK_COUNT
FROM (
SELECT
DECODE(SUBSTR(NAME, 5, 3), 'DAT', '1', 'REC', '2', 'ACF', '3', 'OCR', '4', NULL) AS NUM,
TO_CHAR(NAME) AS GROUP_NAME,
TO_CHAR(ROUND(TOTAL_MB / TYPE_N / 1024)) AS TOTAL,
TO_CHAR(ROUND((HOT_USED_MB + COLD_USED_MB) / TYPE_N / 1024)) AS USED,
TO_CHAR(ROUND(FREE_MB / TYPE_N / 1024)) AS FREE,
TO_CHAR(ROUND((HOT_USED_MB + COLD_USED_MB) / TOTAL_MB * 100)) AS USE_PCT,
X.OS_MB AS DISK_SIZE,
DECODE(SUBSTR(NAME, 5, 4), 'DATA', (SELECT TO_CHAR(COUNT(*)) FROM V$ASM_DISK WHERE MOUNT_STATUS = 'CLOSED' AND HEADER_STATUS = 'CANDIDATE'), '0') AS DISK_COUNT
FROM (
SELECT
CASE
WHEN TYPE = 'NORMAL' THEN 2
WHEN TYPE = 'HIGH' THEN 3
ELSE 1
END AS TYPE_N,
A.*
FROM V$ASM_DISKGROUP A
) G
(
SELECT
DECODE(SUBSTR(A.DG_NAME, 5, 3), 'DAT', '5', 'REC', '6', 'ACF', '7', 'OCR', '8', NULL) AS NUM,
A.*
FROM (
SELECT
'DISK_SIZE' AS DISK_SIZE,
TO_CHAR(SUBSTR(NAME, 1, INSTR(NAME, '_', -1) - 1)) AS DG_NAME,
TO_CHAR(ROUND(OS_MB / 1024)) AS OS_MB
FROM V$ASM_DISK
GROUP BY SUBSTR(NAME, 1, INSTR(NAME, '_', -1) - 1), OS_MB
) A
WHERE A.DG_NAME IS NOT NULL
) X
WHERE G.NAME = X.DG_NAME
) A
ORDER BY NUM;쿼리를 직접 타이핑하다보니 오타가 있을 수 있다.
그럴 경우 쿼리를 쪼개서 수행시켜 보고 오타난 부분을 수정해서 사용하기 바란다.
위 쿼리의 결과는 아래와 같다
| GROUP_NAME | TOTAL_GB | USED_GB | FREE_GB | USE_PCT_PER | DISK_SIZE_GB | DISK_COUNT |
|---|---|---|---|---|---|---|
| XXX_DATA | 28599 | 272520 | 13078 | 95 | 500 | 31 |
| XXX_RECO | 5600 | 494 | 5105 | 9 | 500 | 0 |
| XXX_OCR | 15 | 1 | 14 | 3 | 10 | 0 |
각 컬럼의 의미
- GROUP_NAME : ASM DISK GROUP 이름.
- TOTAL_GB : 할당된 전체 공간. GB단위
- USED_GB : 사용중인 공간. GB단위
- FREE_GB : 여유 공간. GB단위
- USE_PCT_PER : 사용중인 공간. % 단위
- DISK_SIZE_GB : ASM DISK별 사이즈. GB단위
- DISK_COUNT : 여분 DISK 갯수.
DECODE를 사용한 이유는
GROUP NAME의 오름차순,내림차순 정렬이 아닌
중요도 순으로 정렬하기 위해
ASM DISK GROUP을 중요도순으로 번호를 부여하고 이 번호를 정렬했다.
회사마다 ASM이름이 다르겠으나
일반적으로 DATA,RECO,OCR 과 같은 형식으로 분류하여 사용할 것이다.
본인 환경에 맞게 수정하여 사용하면 된다.
'└ 01-02.ORACLE > SQL' 카테고리의 다른 글
| 오라클 DB계정 생성 ORACLE CREATE USER (0) | 2024.01.16 |
|---|---|
| ORACLE RMAN 백업 진행 상황을 확인하는 쿼리 RMAN Backup status check (2) | 2023.12.05 |
| 오라클 HWM와 실제로 사용하는 블록 확인 쿼리. 리오그 대상 찾는법. ORACLE REORG HWM (0) | 2023.12.01 |